

引言
随着大数据时代的到来,数据分析和预测变得越来越重要。在众多的数据预测领域中,新奥门资料免费单双预测因其独特的魅力和挑战性而备受关注。本文将详细介绍新奥门资料免费单双预测的原理、方法以及数据支持设计,为读者提供一个全面的视角。
新奥门资料免费单双预测的原理
新奥门资料免费单双预测,顾名思义,是指通过对历史数据的分析,预测未来某一事件的发生概率。在新奥门资料免费单双预测中,我们通常关注的是两个可能的结果:单和双。通过对历史数据的挖掘和分析,我们可以找出一些潜在的规律和趋势,从而对下一次事件的结果进行预测。
新奥门资料免费单双预测的方法
新奥门资料免费单双预测的方法有很多,以下是一些常见的方法:
1. 统计分析法:通过对历史数据的统计分析,找出单双出现的概率分布,从而预测未来事件的结果。
2. 机器学习方法:利用机器学习算法,如决策树、随机森林、支持向量机等,对历史数据进行训练和预测。
3. 时间序列分析法:通过对时间序列数据的分析,找出单双出现的时间规律,从而预测未来事件的结果。
4. 深度学习方法:利用深度学习算法,如卷积神经网络、循环神经网络等,对历史数据进行训练和预测。
数据支持设计的重要性
在新奥门资料免费单双预测中,数据支持设计起着至关重要的作用。一个优秀的数据支持设计可以提高预测的准确性和稳定性,从而为决策提供有力的支持。以下是数据支持设计的主要内容:
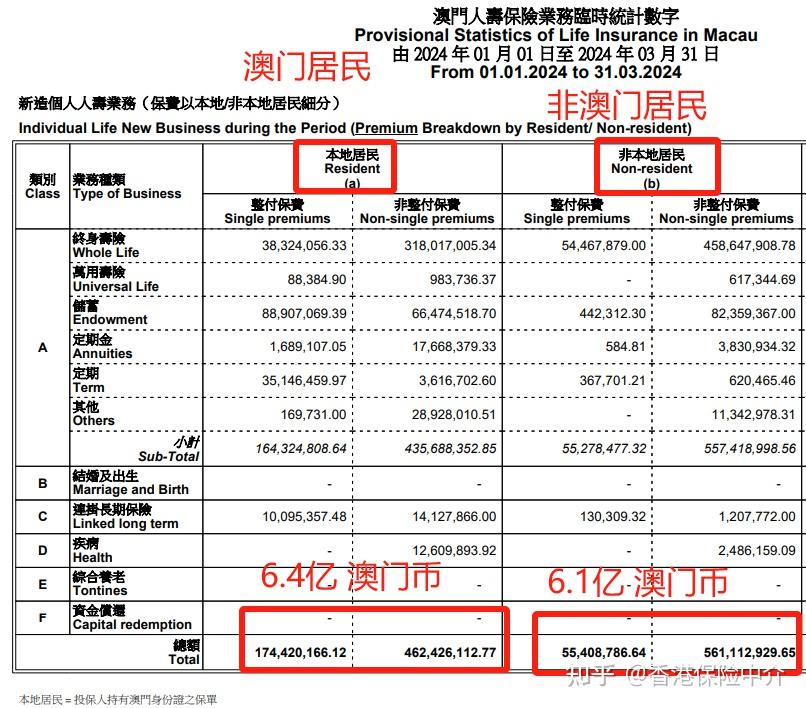
1. 数据收集:收集历史数据是数据支持设计的第一步。我们需要收集尽可能多的历史数据,以确保数据的全面性和准确性。
2. 数据清洗:对收集到的数据进行清洗,去除异常值和噪声,以提高数据的质量。
3. 特征工程:对清洗后的数据进行特征提取和特征选择,以找出对预测结果有影响的关键特征。
4. 数据分割:将数据集分割为训练集、验证集和测试集,以评估模型的性能。
5. 数据增强:通过数据增强技术,如过采样、欠采样、合成数据等,提高数据的多样性和代表性。
M版54.785数据支持设计案例分析
M版54.785是新奥门资料免费单双预测中的一个典型案例。以下是M版54.785数据支持设计的详细步骤:

1. 数据收集:收集过去5年的M版54.785历史数据,共计10000条记录。
2. 数据清洗:对收集到的数据进行清洗,去除异常值和噪声,最终得到9000条有效记录。
3. 特征工程:对清洗后的数据进行特征提取和特征选择,共提取出10个关键特征,包括单双出现的次数、频率、时间间隔等。
4. 数据分割:将数据集分割为训练集、验证集和测试集,比例为7:2:1。
5. 数据增强:通过过采样和欠采样技术,提高数据的多样性和代表性。
6. 模型训练:利用随机森林算法对训练集进行训练,得到一个预测模型。

7. 模型评估:利用验证集和测试集对模型进行评估,评估指标包括准确率、召回率、F1分数等。
8. 模型优化:根据评估结果,对模型进行优化,提高预测的准确性和稳定性。
结论
新奥门资料免费单双预测是一个复杂且具有挑战性的任务。通过对历史数据的分析和挖掘,我们可以找出一些潜在的规律和趋势,从而对下一次事件的结果进行预测。数据支持设计在新奥门资料免费单双预测中起着至关重要的作用,一个优秀的数据支持设计可以提高预测的准确性和稳定性。M版54.785数据支持设计案例分析为我们提供了一个成功的实践案例,值得借鉴和学习。
总之,新奥门资料免费单双预测是一个值得深入研究的领域,它不仅可以帮助我们更好地理解和预测未来事件,还可以为决策提供有力的支持。随着技术的不断发展和进步,新奥门资料免费单双预测将在未来发挥越来越重要的作用。
转载请注明来自法游天下(北京)法律咨询有限公司,本文标题:《新奥门资料免费单双,数据支持设计_M版54.785》







 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号
还没有评论,来说两句吧...